智源研究院:原生多模态世界模型Emu3发布, 实现视频、图像、文本大一统
10月23日下午消息,智源研究院近日宣布原生多模态世界模型Emu3发布。该模型实现了视频、图像、文本三种模态的统一理解与生成。据悉,Emu3只基于下一个token预测,无需扩散模型或组合式方法,便能把图像、文本和视频编码为一个离散空间,在多模态混合序列上从头开始联合训练一个Transformer,展现了其在大规模训练和推理上的潜力。
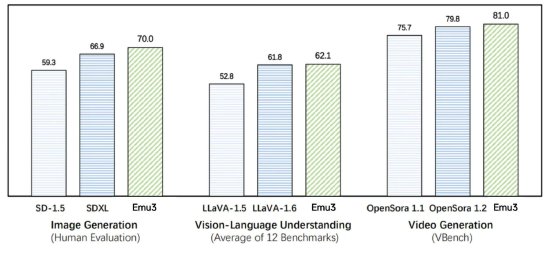
在图像生成、视觉语言理解、视频生成任务中,Emu3的表现超过了 SDXL 、LLaVA-1.6、OpenSora等知名开源模型。在图像生成任务中,人类评估得分Emu3高于SD-1.5与SDXL;在视觉语言理解任务中,12 项基准测试的平均得分,Emu3领先于LlaVA-1.6与LlaVA-1.5;在视频生成任务中,VBench基准测试得分,Emu3优于OpenSora 1.2。
下一token预测被认为是通往AGI的可能路径,但这种范式在语言以外的多模态任务中没有被证明。此前,多模态生成任务仍然由扩散模型(例如 Stable Diffusion)所主导,而多模态理解任务则由组合式的方法(例如 CLIP视觉编码器与LLM结合)所主导。智源研究院院长王仲远表示:“Emu3证明了下一个token预测能在多模态任务中有高性能的表现,这为构建多模态AGI提供了广阔的技术前景。Emu3有机会将基础设施建设收敛到一条技术路线上,为大规模的多模态训练和推理提供基础,这一简单的架构设计将利于产业化。未来,多模态世界模型将促进机器人大脑、自动驾驶、多模态对话和推理等场景应用。”
目前,智源研究院已将Emu3的关键技术和模型开源至国际技术社区。相关技术从业者表示:“对于研究人员来说,Emu3意味着出现了一个新的机会,可以通过统一的架构探索多模态,无需将复杂的扩散模型与大语言模型相结合。这种方法类似于transformer在视觉相关任务中的变革性影响。”
相关文章
刚刚,A50、A股拉升!这个板块多股涨停
专题:A股是全球最具吸引力的市场之一 跨年行情值得期待...

美疫苗股抛售加剧!分析师:小肯尼迪给整个行业带来了不确定性
美东时间周五,疫苗制造商的股票连续第二天大跌。华尔街分析师警告称,特朗普选中疫苗怀疑论者小肯尼迪担任卫生部长,这将给整个生物技术行业带来巨大的不确定性。...

冯喜运:现货黄金美原油期货最新行情走势分析
11月1...


突发!拉响密集防空警报!以色列宣布:在未来48小时内进入紧急状态!
当地时间25日,黎巴嫩真主党发表声明,宣布向以色列发射大量无人机和火箭弹,就上个月以军空袭黎巴嫩首都贝鲁特南郊炸死其军事领导人舒库尔一事对以色列进行报复。...
增利不增收 “零售银行双王”居安思危
专题:聚焦2023上市银行年报...